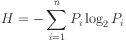
We've looked at some of the ways we can measure the performance of supervised learning on a particular task, e.g., through calculation of error rate.
Is there any general way of working out how good a model really is?
Can we measure how much knowledge it contains?
Concepts of information theory are of use here.
This becomes a way of working out how much is already known in a particular situation, and therefore how much can be learned from new data.
Your actual level of uncertainty depends on the probabilities you give to the two possibilities.
The best case is where you can give all probability to one case:
P(palacePier) = 1.0 P(westPier) = 0.0The worst case is the 50/50 situation where
P(palacePier) = 0.5 P(westPier) = 0.5Semi-flat distributions express intermediate amounts of uncertainty.
Uncertainty increases with the flatness of the distribution applied.
If the txt suggests meeting outside the cinema, you'd then have three possible interpretations: Odean, Cinecentre and DoY.
Someone faced with three equally probable alternatives has to be more uncertain than someone faced with two equally probable alternatives.
So the total number of alternatives must also contribute to level of uncertainty.
It's not necessary to understand why or how this works. (Although you may need to implement it in Java.)
The point to remember is that this calculation meets the
requirements for an uncertainty measure: its values get
bigger with both the flatness and range of the probability
distribution  .
.
He was interested in the possibility of quantifying amounts of information.
He proposed that we can quantify information in terms of reduction of uncertainty.
Using this idea, it becomes possible to measure the amount of information conveyed by signals.
We can also use the idea to evaluate coding schemes.
P(Brighton) = 1/4 P(PrestonPark) = 1/4 P(Hove) = 1/4 P(LondonRoad) = 1/4The entropy for this, with logs taken to base 2, turns out to be exactly 2.0.
Spot the coincidence.
It's also the number of binary digits we need to represent four different cases (which is really the same thing).
An optimal digital code to represent the four stations is thus found to use just two binary digits.
(What would we get for the stations distribution if we calculate entropy with logs taken to base 4?)
The one niggle is the likelihood of getting back a non-integer entropy when we have a distribution that is not perfectly flat.
In this case, we have to round up to get the required number of questions/digits.
A coding scheme is said to be redundant if the number of codes deployed is more than the number required.
The amount of redundancy is just the number of surplus codes used.
Working information values out, we usually work on the basis of logs measured to base 2. The digits identified through entropy measurement then have 2 values; information theorists call them `bits', as a contraction of `BInary digiTS'.
We need just 2 binary digits (bits) to specify one of four stations.
If we were to use 3 binary bits, we would then have 1 bit of redundancy.
(Note: `bits' in information theory are slightly different from `bits' in computer science.)
But the predictions forthcoming will always be uncertain to some degree, i.e., they will be probabilistic in nature.
Information theory then offers a way of assessing the general quality of the model, as a `store of knowledge' about the data.
The amount of uncertainty elimianted by a model quantifies the knowledge it encapsulates.
Information-theoretic measurements can be a way of guiding and evaluation model construction.
The next two lectures will look at a useful application of this idea.
 ensures entropy value
is a measure of the number of -way digits/questions
required.
ensures entropy value
is a measure of the number of -way digits/questions
required.