

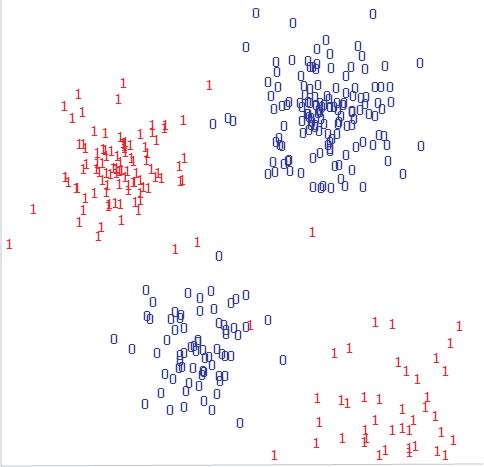
Enjoyment seems to be more likely if the individual's datapoint is near to a lot of 1s.
This suggests predicting enjoyment if the individual's datapoint is within one of the two clumps of 1s.
The data need to be modeled in a way that lets us work out which clump a particular individual falls near to.
Alternatively, we can take a shortcut and use the nearest neighbour method, also known by the acronym NN.
No looking for patterns.
No modeling.
To guard against this it is common to base predictions on several datapoints; i.e., we predict the value that is most common among k nearest datapoints.
This version of the method is known as k-NN, with k representing the number of nearest neighbours taken into account.
With continuous data, the best approach is to average.
With categorical data, we can take the mode instead (i.e., most commonly seen value).
The direct-line distance between two points can be worked out using the Pythagorean formula. It is the square root of the sum of the squares of the differences between corresponding values.

where  is the i'th value of datapoint
is the i'th value of datapoint  and
and  is the i'th element of datapoint
is the i'th element of datapoint  .
.
This is also known as the Euclidean distance.
Informally, it is the `as the crow flies' distance.
VL TC
A 16 3
B 17 4
Euclidean distance between A and B is then

If this seems inappropriate, it is better to use the city-block distance.
This is just the sum of absolute differences between corresponding values.

Rather than measuring the `as the crow flies' distance, this measures the distance walking up and down blocks.
We can use use a hand-crafted differencing function.
More simply, we can just treat identical values as having a difference of zero and non-identical values as having a difference of 1.
With real data, this is unlikely to be the case.
We need to standardize the ranges, through normalisation.
If we don't do this, distances between variables with larger ranges will be over-emphasised.
We take each number in turn and subtract from it the minimum observed value.
We then divide by the observed range of values.
The result is a number between 0.0 and 1.0.
X Y 3 -0.2 4 0.8 9 0.3
After normalisation
X Y
3 / 10 = 0.3 (-0.2 + 1) / 2 = 0.4
4 / 10 = 0.4 (0.8 + 1) / 2 = 0.9
9 / 10 = 0.9 (0.3 + 1) / 2 = 0.65
But what happens if we get given some categorical data?
The easiest approach is just to convert them into numeric data.
Sparsification is a safe way of doing this.
It involves creating a new binary (0/1) variable to represent every non-numeric value of every original variable.
A new, continuous dataset is created by recoding the original data in terms of the binary variables.
COLOUR SHAPE red ball blue box red box blue post
Encode as 1s and 0s with values mapped to positions like this.
red? blue? ball? box? post?
So red ball becomes <1 0 1 0 0>
Also known as inductive inference, this is the process on which scientific knowledge is assembled.
The basic approach of machine learning is essentially the basic approach of science.
This highlights the degree to which science is always a kind of guesswork.
Scientific laws can turn out to be wrong, as we know from the example of black swans.
On the basis of observing many white swans in Europe the inductive inference was drawn that all swans are white.
Then it turned out there are black swans to be found in Australia.
.